- New and Exciting Content
- Why Hugging Face transformer
- Will we in this lecture fine-tune a pretrained NLP model with HF rather than fastai library?
- Why use transformer rather than fastai library?
- Is Jeremy in the process of integrating transformer into fastai library?
- Does transformer has the same layered architecture of fastai? Is it high level enough?
- Why it is a good thing to use a reasonably high level library (not as high as fastai)?
- Understand Fine-tuning
- Do we have the foundations to understand the details of fine-tuning now?
- How to understand pretrained model in terms of parameters confidence? 03:51
- Is fine-tuning trying to increase on the parameters which are not confident?
- ULMFiT: the first fine-tuned NLP model
- Where this model was first developed and taught?
- Who wrote the paper?
- What’s its impact?
- ULMFiT step 1: a language model from scratch
- What is the first language model in step one?
- What’s the model trying to predict? What’s the dataset?
- Why is this task so difficult? 06:10
- How much knowledge does the model have to understand in order to predict?
- How well can this first model predict in step one?
- Step 2: fine-tuned the first model on IMDB
- How did Jeremy build the second language model?
- Where did the second model start with? What was the dataset for the second model?
- What was the second model good at predicting?
- Step 3: turn a language model to classify
- Labels of language models
- What are the labels for the datasets of the first two models?
- Transformer models vs ULMFiT
- When did the transformers first appear?
- What’s transformers models are built to take advantage of?
- What is not transformers trying to predict? (reason in part 2)
- How transformers modified its dataset and what does it predict? 09:41
- Does ULMFiT and Transformers really differ much on what to predict?
- How much different are the 3 steps between ULMFiT and Transformers?
- What a model knows
- What can lower and higher layers of parameters/weights learn? 11:08
- What we do to those layers of weights for transfer learning? 13:20
- Zeiler and Fergus paper
- NLP beginner on Kaggle competition
- Using a Kaggle competition to introduce NLP for beginners, isn’t it amazing!
- Why we should take Kaggle competition more seriously? 15:06
- What real world tasks can NLP classification do? 15:57
- Examine the competition dataset
- What is inside the competition dataset?
- How classificationish does the dataset look like?
- What do we predict about ‘anchor’ and ‘target’?
- What value to predict?
- Why it is not really a straightforward classification?
- What is the use of ‘context’?
- Model Strategy
- How to modify the dataset in order to turn a similarity problem into a classification problem?
- Should we always try to solve a problem by turning it into a problem we are familiar with?
- Get notebook ready
- When and how to use a GPU on Kaggle?
- Why Jeremy recommend Paperspace over Kaggle as your workstation?
- How easy has Jeremy made it to download Kaggle dataset and work on Paperspace or locally?
- How to do both python and bash in the same jupyter cell?
- Get raw dataset into documents
- How to check what inside the dataset folder?
- Why it is important to read Competition data introduction which is often overlooked?
- How to read a csv file with pandas? 24:30
- What are the key four libraries for data science in python? 24:46
- What is the other book besides fastbook recommended by Jeremy? 25:36
- Why you must read it too?
- How to access and show the dataset in dataframe? 26:39
- How to
describethe dataset? What does it tell us in general? 27:10 - What did the number of unique data samples mean to Jeremy at first? 27:57
- How to create a single string based on the model strategy? 28:26
- How to refer to a column of a dataframe in reading and writing a column data?
- Tokenization: Intro
- How to turn strings/documents into numbers for neuralnet?
- Do we split the string into words first?
- What’s the problem with the Chinese language on words?
- What are vocabularies compared with splitted words?
- What to do with the vocabulary?
- Why we want the vocabulary to be concise not too big?
- What nowadays people prefer rather than words to be included in vocab?
- Subwords tokenization by Transformer
- How to turn our dataframe into Hugging Face
Dataset? - What does HF Dataset look like?
- What is tokenization? What does it do?
- Why should we choose a pretrained model before tokenization?
- Why must we use the model’s vocab instead of making our own?
- How similar is HF model hub to TIMM? 33:10
- What Jeremy’s advice on how to use HF model hub?
- Are there some models generally good for most of practical problems? 34:17
- When did NLP models start to be actually very useful? 34:35
- Why we don’t know much about those models which potentially are good for most of things?
- Why should we choose a small model to start with?
- How to get the tokens, vocabs and related info of the pretrained model? 36:04
- How to tokenize a sentence by the model’s style?
- After a document is splitted into a list of vocab, do we turn the list of vocab into a list of numbers? Numericalization 38:30
- Can you get a sense of what subword vs word is from the examples of tokenization
- How to tokenize all the documents with parallel computing? 38:50
- Given the input column is the document, what’s inside the input_id column?
- How to turn our dataframe into Hugging Face
- Special treatment to build input?
- Do we need to follow some special treatment when building a document or an input from dataset?
- What about when the document is very long?
- Start ULMFiT on large documents
- What ULMFiT is best at doing?
- Why ULMFiT can work on large documents fast and without that much GPU?
- How large is large for a document?
- Some obscure documentations of Transformer library
- The most important idea in ML
- Is it the idea of having separate training, testing, validation datasets?
- Underfitting vs Overfitting
- How to create a function to plot a polynomial function with a degree variable?
- What are 1st/2nd/3rd degree polynomial?
- What does Jeremy think of sklearn? When to use it? 47:37
- What is underfitting? Why a too-simple model is a problem or is systematically biased? 48:12
- What is overfitting? What does an overfit look like? 48:58
- What is the cause of overfitting?
- It is easy to spot underfitting, but how to filter an overfitting from the function we want?
- Validation: avoid overfitting on training set
- How to get a validation dataset and use it?
- Why you need to be careful when use other libraries other than fastai?
- How and Why to create a good validation set
- Did you know simply random 20% of dataset as a validation set is not good enough?
- For example, shouldn’t you select validation dataset so that your model can predict the future rather than the past?
- Why is Kaggle competition a great and real-world way to appreciate using validation set to avoid overfitting?
- How validation set can help avoid overfitting in 2 Kaggle competition on real world problems? 54:44
- Watch out when touching cross-validation 56:03
- Why should you be careful when simply using library-ready tools of selecting validation set randomly?
- Validation post by Rachel
- Test set: avoid overfitting on validation set
- What is a test set for?
- Why need it when we have a validation set?
- When or how can you overfit on a validation set? or
- Why is validation set not enough to overcome model overfitting?
- Why Kaggle prepares two test sets? or
- Why Kaggle thinks that two test sets are enough to filter overfitting models
- Metrics functions vs Loss functions
- How we use validation set to check on the performance of model?
- Will Kaggle competition choose the metrics for you?
- Should the metrics be our loss function?
- What kind of functions you should use as loss function? (bumpy vs smooth)
- So, always be aware: the loss your model tries to beat may not be the same function to rate your model
- Why one metric is always not enough and can cause much problem?
- Metrics: you can’t feel it from math
- What is Pearson correlation (r) and how to interpret it?
- Which can teach you how r behave, its math function or its performance on datasets?
- Should we a plot with a 1000 random data point or a plot with the entire a million data points?
- How to get correlation coefficient for every variable to every other variable? 1:06:27
- How to read the correlation coefficient matrix?
- How to get a single correlation coefficient between two things?
- How to tell how good is a correlation coefficient number? 1:07:45
- What are the things to spot? (tendency line, variation around the line, outliers)
- How to create transparency on the plot?
- How can we tell from another example that r is very sensitive to outliers? 1:09:47
- How much can removing or mess up a few outliers really affect your scores on r? or
- Why do you have to be careful with every row of data when dealing with r?
- Can we know how good is r = 0.34 or r = -0.2 without a plot?
- Don’t forget to get the data format right for HF
- HF train-validation split
- How to do the random split with HF?
- Will Jeremy talk about proper split in another notebook?
- Training a model
- What to use for training a model in HF?
- What is batch and batch size?
- How large should a batch size be?
- How to find a good learning rate? (details in a future lecture)
- Where to prepare all the training arguments in HF library?
- Which type of tasks do we use for picking the model?
- How to create the learner or trainer after model?
- How to train?
- Why is the result on metrics so good right from the first epoch?
- Dealing with outliers
- Should we get a second analysis for the outliers rather than simply removing them?
- What outliers really are in the real world?
- Doesn’t outliers usually tell us a lot of surprisingly useful info than in the limiting statistical sense?
- What is Jeremy’s advice on outliers?
- Predict and submit
- How to do prediction with HF?
- Should we always check the prediction output as well as the test set input?
- What is the common problem with the output? (proper solution may be in the next lecture)
- What is the easy solution?
- How to submit your answer to Kaggle?
- Huge opportunities in research and business
- Misuses of NLP
- Can NLP chatbots can create 99% of online chat which almost non-distinguishable from real humans?
- Can GTP-3 create even longer and more sophisticated prose which is even more human-like?
- How machined generated public opinions can influence public policies or laws?
- Issues on
num_labelsin HF library
摘要Summaries--课时四(Lesson 4)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mfbz.cn/a/609116.html
如若内容造成侵权/违法违规/事实不符,请联系我们进行投诉反馈qq邮箱809451989@qq.com,一经查实,立即删除!相关文章
文章解读与仿真程序复现思路——电力自动化设备EI\CSCD\北大核心《计及全生命周期成本的公交光伏充电站储能优化配置方法》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》
论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html
电网论文源程序-CSDN博客电网论文源…

清华团队开发首个AI医院小镇模拟系统;阿里云发布通义千问 2.5:超越GPT-4能力;Mistral AI估值飙升至60亿美元
🦉 AI新闻
🚀 清华团队开发首个AI医院小镇模拟系统
摘要:来自清华的研究团队最近开发出了一种创新的模拟系统,名为"Agent Hospital",该系统能够完全模拟医患看病的全流程,其中包括分诊、挂号、…
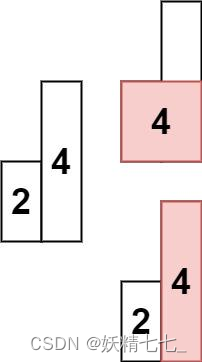
【八十五】【算法分析与设计】单调栈的全新版本,两个循环维护左小于和右小于信息,84. 柱状图中最大的矩形,85. 最大矩形
84. 柱状图中最大的矩形 给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 求在该柱状图中,能够勾勒出来的矩形的最大面积。 示例 1: 输入:heights [2,1,5,6,2,3] 输出:10 解释&am…
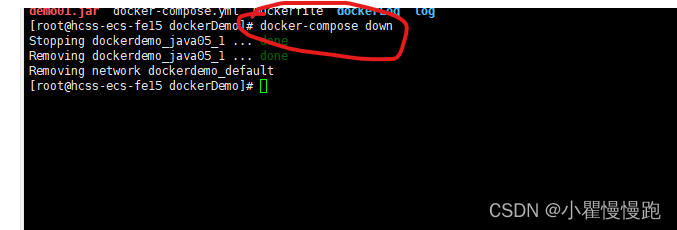
docker-compose部署java项目
docker-compose是定义和运行多容器的工具。换句话说就是通过配置yml文件来运行容器,简化了每次输入docker run等命令,把这些命令配置在yml文件统一管理,而且可以用一个yml文件一次启动多个容器,启动时还可以设置各个容器的依赖关系…
远程开机与远程唤醒BIOS设置
远程开机与远程唤醒BIOS设置
在现代计算机应用中,远程管理和控制已成为许多企业和个人的基本需求。其中,远程开机和远程唤醒是两项非常实用的功能。要实现这些功能,通常需要在计算机的BIOS中进行一些特定的设置。以下是对远程开机和远程唤醒…
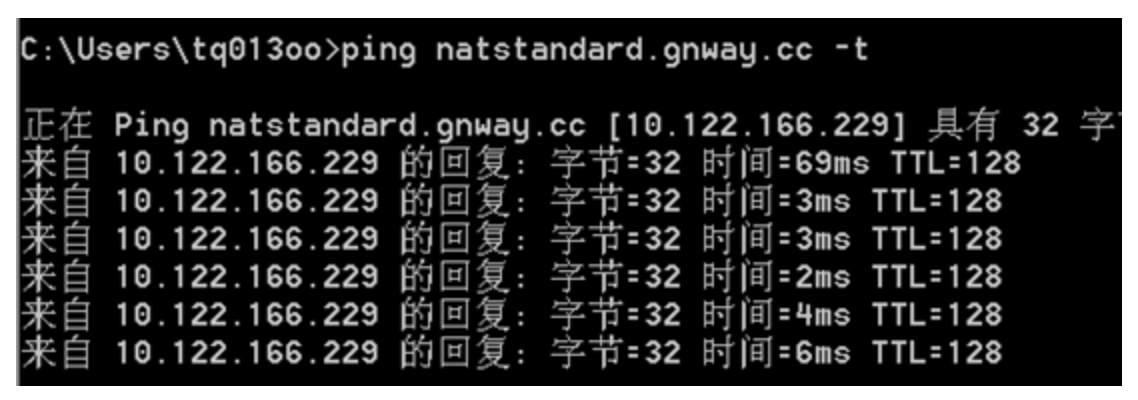
如何判断nat网络?如何内网穿透
大家都清楚,如果你想开车,就必须要给车上一个牌照,随着车辆越来越多,为了缓解拥堵,就需要摇号,随着摇号的人数越来越多,车牌对于想开车的人来说已经成为奢望。在如今的IPv4时代,我们…

全自动减压器法二氧化碳气容量测试仪:饮料行业的革新与未来
全自动减压器法二氧化碳气容量测试仪:饮料行业的革新与未来
一、引言 在追求品质与效率的现代饮料生产领域,全自动减压器法二氧化碳气容量测试仪凭借其高精度、高效率及无人工干预的显著优势,正逐渐成为行业的标杆。特别是在碳酸饮料的生产中…
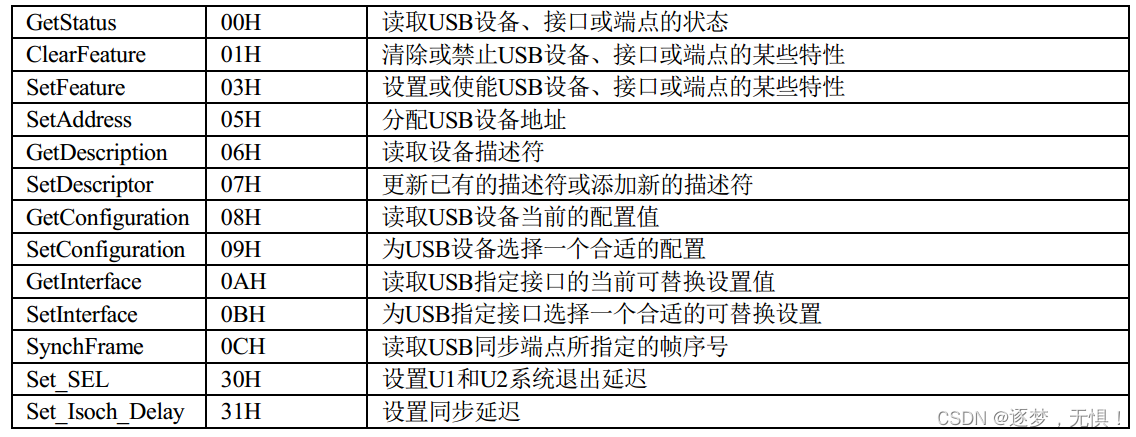
USB系列五:USB设备配置(重要)
在USB总线接口协议中,对于USB外部设备功能特征是通过端点(Endpoint)、配置(Configuration)和接口(Interface)来描述的,这些就是典型的USB描述符。
USB主机通过设备请求来读取外部设…
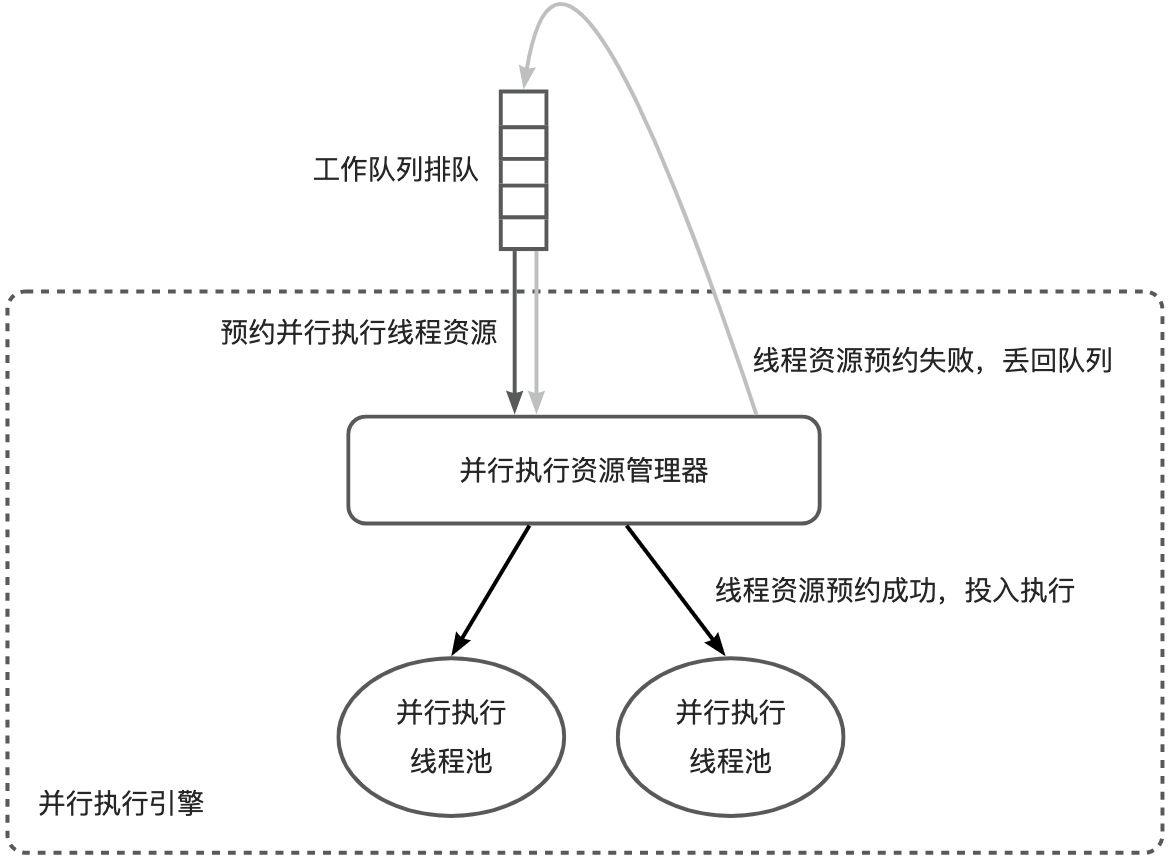
并行执行线程资源管理方式——《OceanBase 并行执行》系列 3
在某些特定场景下,由于需要等待线程资源,并行查询会遇到排队等待的情况。本篇博客将介绍如何管理并行执行线程资源,以解决这种问题。 《OceanBase并行执行》系列的内容分为七篇博客,本篇是其中的第三篇。前2篇如下:
一…
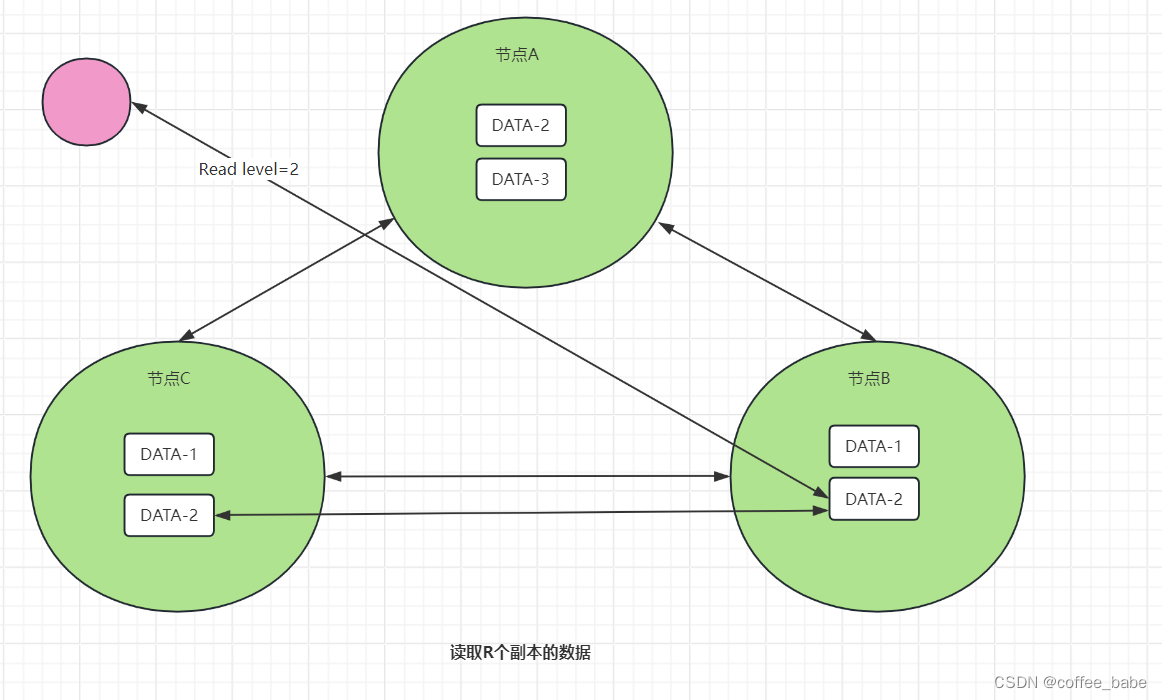
分布式与一致性协议之Quorum NWR算法
Quorum NWR算法
概述
不知道你在工作中有没有遇到过这样的事情:你开发实现了一套AP型分布式系统,实现了最终一致性,且业务接入后运行正常,一切看起来都那么美好。 可是突然有同事说,我们要拉这几个业务的数据做实时分析…
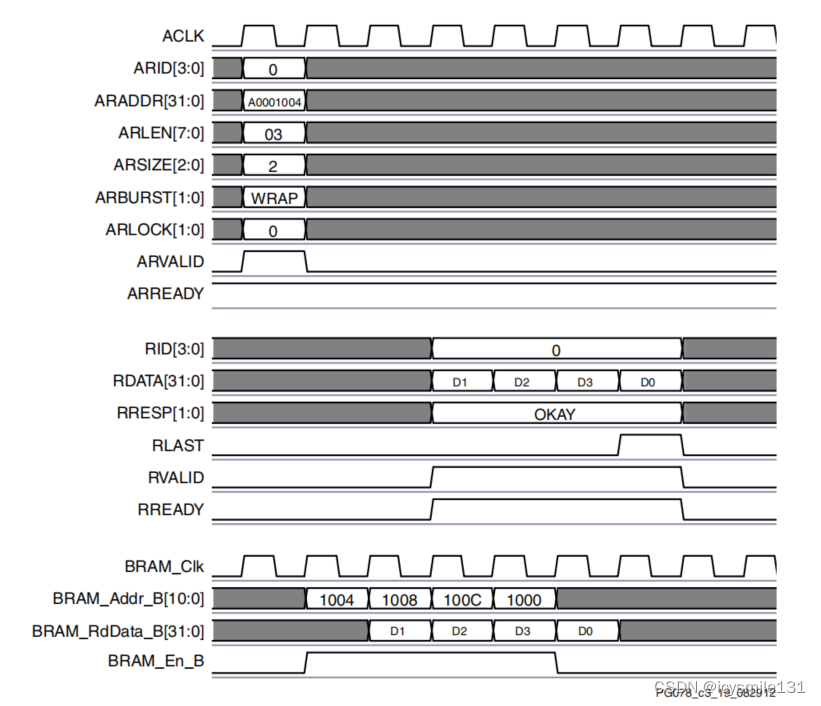
AXI4读时序在AXI Block RAM (BRAM) IP核中的应用
在本文中将展示描述了AXI从设备(slave)AXI BRAM Controller IP核与Xilinx AXI Interconnect之间的读时序关系。
1 Single Read
图1展示了一个从32位BRAM(Block RAM)进行AXI单次读取操作的时序示例。 图1 AXI 单次读时序图
在该…

webpack如何自定义一个loader
我们在使用脚手架的搭建项目的时候往往都会帮我们配置好所需的loader,接下来讲一下我们要如何自己写一个loader应用到项目中(完整代码在最后)
1. 首先搭建一个项目并找到webpack配置文件(webpack.config.js)
在modul…

clickhouse学习笔记06
ClickHouse的建表和引擎选择思路讲解 ClickHouse的常见注意事项和异常问题排查 ClickHouse高性能查询原因剖析-稀疏索引 ClickHouse高性能写入剖析-LSM-Tree存储结构

嵌入式开发十:STM32开发基础入门知识补充
本篇博客主要是针对前面STM32入门基础知识的补充,为后面的真正开发学习做好准备。
目录
一、IO 引脚复用器和映射 1.1 引脚复用的概念
1.2 如何设计实现复用
1.3 复用功能固件库配置过程
二、STM32 NVIC 中断优先级管理 2.1 NVIC中断优先级管理结构体介绍 …

力扣每日一题-统计已测试设备-2024.5.10
力扣题目:统计已测试设备
题目链接: 2960.统计已测试设备
题目描述 代码思路
根据题目内容,第一感是根据题目模拟整个过程,在每一步中修改所有设备的电量百分比。但稍加思索,发现可以利用已测试设备的数量作为需要减少的设备电…
16地标准化企业申请!安徽省工业和信息化领域标准化示范企业申报条件
安徽省工业和信息化领域标准化示范企业申报条件有哪些?合肥市 、黄山市 、芜湖市、马鞍山、安庆市、淮南市、阜阳市、淮北市、铜陵市、亳州市、宣城市、蚌埠市、六安市 、滁州市 、池州市、宿州市企业申报安徽省工业和信息化领域标准化示范企业有不明白的可在下文了…

机器学习各个算法的优缺点!(上篇) 建议收藏。
下篇地址:机器学习各个算法的优缺点!(下篇) 建议收藏。-CSDN博客
今天有朋友聊起来,机器学习算法繁多,各个算法有各个算法的特点。
以及在不同场景下,不同算法模型能够发挥各自的优点。
今天…

深化产教融合,泰迪智能科技助力西南林业大学提质培优
2024年5月7日,泰迪智能科技昆明分公司院校部总监查良红和数据部负责人余雄亮赴西南林业大学理学院就工作室共建事宜进行交流会谈。西南林业大学理学院院长张雁、党委副书记魏轶、副院长谢爽、就业负责人罗丽及学生代表参与本次交流会。 会议伊始,谢副院长…
最新文章
- Pikachu 靶场敏感信息泄露通关解析
- c语言中数字字符串和数字互转
- 文档分类FastText模型 (pytorch实现)
- 程序员的实用神器之——通义灵码
- 回顾那些年的软件霸主,如今依然让人难以忘怀的经典之作
- 穷人翻身的秘诀!2024年普通人如何创业赚钱?穷人如何逆袭翻身?普通人创业新风口?
- 基于python+Django的二维码生成算法设计与实现
- [Go] 结构体不初始化仍然能够调用其方法
- iZotope RX 11 for Mac:音频修复的终极利器
- Qt---信号和槽
- pytest的测试标记marks
- 解决github无法克隆私有仓库,Repository not found问题(2024最新)
- NFTScan 升级 Bitcoin NFT 浏览器,全面优化 NFT 数据解析体系
- k8s证书续期
- window golang 升级版本
- 运维自动化工具:Ansible 概念与模块详解
- 消息队列选型
- 揭秘奇葩环境问题:IDEA与Maven版本兼容性解析
- 【字符串】Leetcode 12. 整数转罗马数字【中等】
- springboot报错‘url’ attribute is not specified and no embedded datasource could
- 尽微好物:从0到10亿+的抖音电商的TOP1“联盟团长”,如何使用NineData实现上云下云
- 什么是IP地址?
- 问题与解决:element plus对话框背景色覆盖失效
- python 合并 pdf
- ------- 计算机网络基础
- Sora:OpenAI的革命性AI视频模型与其对未来影像创作的影响
- 「Python大数据」VOC数据清洗
- 分享1.36G全国村名点数据
- 数据结构—栈操作经典案例
- # 从浅入深 学习 SpringCloud 微服务架构(十四)微服务链路追踪